¿Qué es un token? Cómo funciona y para qué sirve en ChatGPT
- ¿Qué es un token? Cómo funciona y para qué sirve en ChatGPT
- Primero aclaremos algo: token no es criptomoneda
- Qué es realmente un token en ChatGPT
- Cómo funciona la tokenización dentro del modelo
- Por qué los tokens determinan el límite de ChatGPT
- Cómo los tokens afectan el costo al usar la API
- Cómo escribir mejores prompts entendiendo los tokens
- Pensar en tokens es pensar como el modelo
Cuando escuchas la palabra token, es fácil pensar en criptomonedas, blockchain o activos digitales. Y ahí comienza la confusión. Porque cuando hablamos de ¿qué es un token en ChatGPT?, no estamos hablando de finanzas. Estamos hablando de la unidad mínima con la que el modelo procesa el lenguaje.
Aquí está la hipótesis que debes tener clara desde el inicio: ChatGPT no “lee palabras”. Lee tokens. Y esa diferencia cambia completamente cómo debes entender sus límites, sus respuestas y hasta el costo cuando usas la API.
Un token no es exactamente una palabra. Tampoco es exactamente un carácter. Es una fragmentación intermedia del texto que el modelo convierte en números para poder procesarlo internamente. Antes de que tú veas una respuesta, lo que ocurrió fue una secuencia matemática sobre tokens.
Si no entiendes esto, estás interactuando con la herramienta sin comprender su arquitectura real.
Primero aclaremos algo: token no es criptomoneda
Tu propio texto mezcla ambos conceptos , y ese es un error común en internet.
En blockchain, un token puede representar un activo digital o un derecho de uso. En cambio, en inteligencia artificial y procesamiento de lenguaje natural, un token es una unidad de texto.
Son conceptos distintos que comparten nombre.
En el contexto de los modelos de lenguaje —como los explicados en el artículo técnico — los tokens son fragmentos de texto que el modelo utiliza como entrada y salida. Y según la documentación oficial , los tokens son la base del conteo de uso, límites de contexto y facturación.
Aquí no hay blockchain.
Hay representación numérica del lenguaje.
Qué es realmente un token en ChatGPT
Si quieres entender qué es un token en ChatGPT, debes cambiar la forma en que imaginas el texto.
Para ti, una oración está compuesta por palabras.
Para el modelo, está compuesta por tokens.
Un token es una unidad mínima de procesamiento que puede ser:
- Una palabra completa.
- Una parte de una palabra.
- Un signo de puntuación.
- Un espacio con texto.
- Incluso parte de un número o un emoji.
No es lingüística tradicional. Es ingeniería.
Según la explicación técnica y la documentación oficial , antes de que el modelo procese tu mensaje, el texto se fragmenta en tokens y cada uno se convierte en un identificador numérico. Esos números son los que realmente “lee” el sistema.
ChatGPT no entiende texto. Entiende secuencias numéricas que representan tokens.

Token como unidad mínima de procesamiento
Imagina que escribes:
“ChatGPT es útil”
Para ti son tres palabras.
Para el modelo pueden ser cinco tokens o más, dependiendo de cómo se dividan internamente.
Un token puede incluir un espacio inicial, puede dividir una palabra en sub-fragmentos o puede representar caracteres especiales. La tokenización no sigue reglas gramaticales humanas. Sigue patrones estadísticos aprendidos durante el entrenamiento.
Por eso una misma palabra puede generar distintos tokens dependiendo de su posición o contexto .
Lo que parece simple, internamente es matemático.
Diferencia entre carácter, palabra y token
Aquí es donde se aclara el mito.
- Un carácter es una letra individual.
- Una palabra es una unidad semántica humana.
- Un token es una unidad estadística optimizada para procesamiento.
Si tokenizaras por carácter, el modelo necesitaría procesar secuencias enormes.
Si tokenizaras por palabra completa, el vocabulario sería inmenso y poco eficiente.
La tokenización es un punto intermedio.
Divide el texto en fragmentos frecuentes y reutilizables. Eso reduce tamaño del vocabulario y optimiza memoria y cálculo. Es una solución de ingeniería, no de gramática.
Y ahora que entiendes qué es un token, la pregunta cambia.
¿Cómo funciona exactamente esa transformación de texto a números dentro del modelo?
Eso es lo que veremos a continuación.
Cómo funciona la tokenización dentro del modelo
Ahora que ya sabes qué es un token en ChatGPT, el siguiente paso es entender el proceso que lo convierte en algo utilizable por el modelo.
Porque el modelo no trabaja con texto. Trabaja con números.
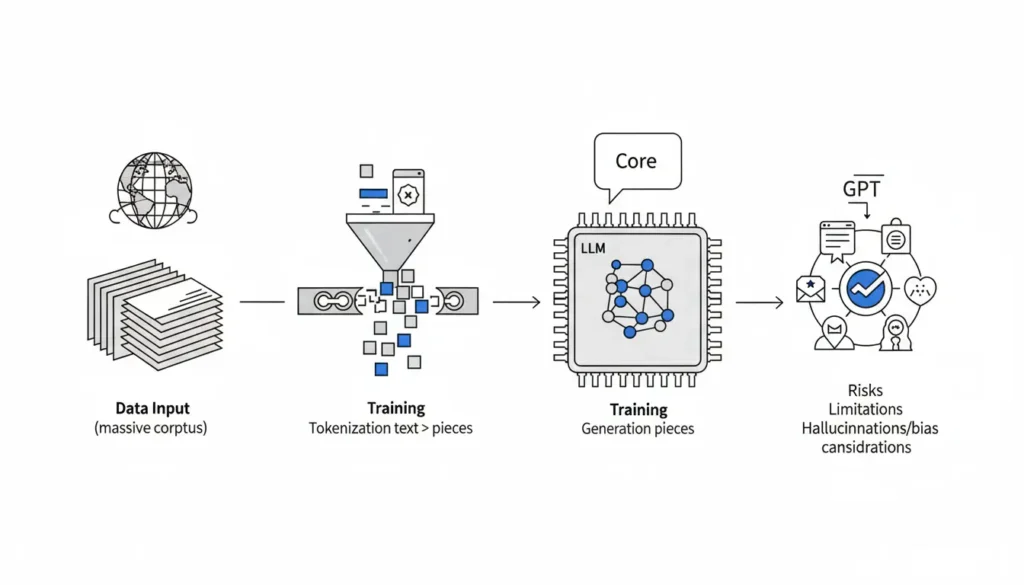
Cuando escribes una frase, ocurre algo que no ves: el sistema la divide en tokens, asigna a cada token un identificador numérico y luego transforma esos identificadores en vectores matemáticos que el modelo puede procesar.
Ese proceso se llama tokenización.
Texto → tokens → números
Primero, tu texto se fragmenta en tokens usando un vocabulario predefinido. Ese vocabulario fue construido analizando grandes volúmenes de texto para detectar fragmentos frecuentes y eficientes .
Luego, cada token se convierte en un número. Ese número no tiene significado semántico humano. Es simplemente un índice dentro del vocabulario.
Por ejemplo:
“Red” al inicio de una oración no necesariamente comparte el mismo identificador que “ red” en medio de una frase . La capitalización y el espacio cambian el token.
Eso significa que el modelo no ve “palabras iguales”. Ve tokens diferentes según contexto.
Embeddings y representación numérica
Después de convertir tokens en identificadores, esos números se transforman en vectores de alta dimensión llamados embeddings.
Un embedding es una representación matemática que captura relaciones estadísticas entre tokens. Tokens que aparecen en contextos similares tienden a ubicarse en regiones cercanas dentro del espacio vectorial.
Aquí ocurre algo importante.
El modelo no entiende significado como tú. Detecta patrones de co-ocurrencia. Aprende probabilidades de qué token suele seguir a otro.
La generación de texto no es “comprensión consciente”. Es predicción estadística token por token.
Y ahora empieza a ser evidente por qué esto importa tanto.
Si ChatGPT opera en tokens, entonces sus límites, su memoria y hasta su costo dependen directamente de ellos.
Por qué los tokens determinan el límite de ChatGPT
Aquí es donde la teoría se vuelve práctica.
Entender qué es un token en ChatGPT no es solo una curiosidad técnica. Es lo que explica por qué el modelo a veces “olvida” partes de la conversación o acorta sus respuestas.
ChatGPT no tiene un límite de palabras. Tiene un límite de tokens.
Ese límite incluye:
- Tu mensaje.
- El historial de la conversación.
- Las instrucciones del sistema.
- Y la respuesta que el modelo va a generar.
Todo suma dentro del mismo espacio de contexto.
Límite de contexto
Cada modelo tiene una capacidad máxima de tokens que puede manejar en una sola interacción. La documentación oficial explica que el límite siempre es combinado: entrada más salida .
Eso significa que si tu prompt consume muchos tokens, la respuesta disponible será más corta. No porque el modelo no pueda responder, sino porque no tiene espacio suficiente dentro del contexto activo.
Piensa en ello como una ventana de memoria.
Si llenas la ventana con instrucciones largas, ejemplos extensos y conversación previa, el modelo debe descartar partes anteriores o limitar su salida.
No es un fallo. Es una restricción estructural.
Entrada + salida: la suma invisible
Cuando usas ChatGPT en modo API, cada token cuenta. Según la documentación técnica , el uso se divide en:
- Tokens de entrada.
- Tokens de salida.
- En algunos modelos, tokens internos de razonamiento.
Aunque no veas el conteo directamente en la interfaz básica, el sistema siempre está midiendo esa suma.
Por eso a veces, en conversaciones largas, el modelo pierde detalles iniciales. El contexto se desplaza y los tokens más antiguos quedan fuera de la ventana activa.
Y aquí aparece la siguiente implicación crítica.
Si los tokens determinan el límite, también determinan el costo cuando usas la API profesionalmente.
Cómo los tokens afectan el costo al usar la API
Hasta ahora hemos hablado de límites. Ahora toca hablar de dinero.
Cuando usas ChatGPT desde la interfaz pública, no ves el conteo. Pero cuando trabajas con la API, cada token procesado tiene un costo. Y ese costo se calcula sobre la suma de tokens de entrada y tokens de salida .
Aquí es donde entender qué es un token deja de ser teórico.
Si envías un prompt de 2.000 tokens y el modelo genera una respuesta de 1.000 tokens, el sistema facturará 3.000 tokens procesados. No importa si el texto es repetitivo o elegante. Lo que cuenta es el volumen tokenizado.
Esto tiene tres implicaciones estratégicas.
Primero, prompts más largos no siempre son mejores. Si agregas contexto innecesario, aumentas costo y reduces margen de respuesta dentro del límite de contexto.
Segundo, respuestas innecesariamente extensas incrementan facturación sin necesariamente aportar más valor.
Tercero, conversaciones largas acumulan tokens. Incluso si cada interacción es breve, el historial completo se vuelve parte del conteo.
No es solo escribir bien. Es escribir eficientemente.
Y aquí ocurre algo interesante.
Entender tokens no solo te ayuda a controlar costos o evitar límites. También te ayuda a diseñar mejores prompts. Porque si sabes cómo el modelo fragmenta y procesa el texto, puedes estructurar instrucciones más claras y compactas.
Cómo escribir mejores prompts entendiendo los tokens
Ahora que ya sabes qué es un token en ChatGPT y cómo afecta límites y costo, la pregunta estratégica es otra: ¿cómo usar ese conocimiento a tu favor?
Si el modelo piensa en tokens y no en párrafos elegantes, entonces tu forma de escribir prompts debe adaptarse a esa lógica. No se trata de adornar. Se trata de estructurar.
Un prompt eficiente no es el más largo. Es el más claro dentro del menor número de tokens posibles.
Compresión inteligente
La primera mejora viene de eliminar redundancia.
Si repites instrucciones, agregas contexto innecesario o usas frases largas sin aportar precisión, estás consumiendo tokens sin mejorar resultado.
En lugar de escribir:
“Necesito que por favor me ayudes a generar una explicación lo más clara posible sobre…”
Puedes escribir:
“Explica de forma clara y estructurada…”
El modelo no necesita cortesía. Necesita instrucciones precisas.
Cada token cuenta dentro del límite de contexto y dentro del costo en API .
Estructura clara sobre texto decorativo
Los modelos funcionan mejor cuando la información está organizada.
En lugar de bloques densos, utiliza:
- Instrucciones numeradas.
- Requisitos específicos.
- Objetivo definido.
- Formato esperado.
Esto no aumenta necesariamente el número de tokens, pero sí mejora la interpretación. Porque reduces ambigüedad.
Recuerda: el modelo predice token por token. Si tu instrucción es ambigua, las probabilidades se dispersan. Si es precisa, la predicción se concentra.
Comprender tokens no es técnico por gusto. Es práctico.
Te permite:
- Controlar longitud.
- Optimizar costo.
- Evitar recortes por límite.
- Obtener respuestas más coherentes.
Y ahora podemos cerrar el círculo.
Si entiendes los tokens, empiezas a pensar como el modelo.
Eso cambia completamente tu forma de interactuar con ChatGPT.
Pensar en tokens es pensar como el modelo
Si llegaste hasta aquí, ya deberías ver que qué es un token en ChatGPT no es una curiosidad técnica. Es la base de cómo funciona todo el sistema.
ChatGPT no procesa “ideas”. Procesa tokens.
No recuerda “temas”. Recuerda secuencias dentro de un límite de tokens.
No genera “respuestas conscientes”. Predice el siguiente token más probable.
Entender esto cambia tu mentalidad.
Cuando escribes un prompt, ya no piensas en párrafos largos. Piensas en claridad estructural. Cuando una respuesta se corta, ya no lo atribuyes a capricho. Lo entiendes como límite de contexto. Cuando usas la API, ya no ves el costo como algo abstracto. Lo ves como volumen tokenizado .
Y aquí está la implicación más importante.
Si no entiendes los tokens, estás usando ChatGPT desde la superficie.
Si entiendes los tokens, empiezas a interactuar desde la arquitectura.
La diferencia no está en escribir más. Está en escribir mejor dentro del espacio que el modelo realmente puede procesar.
Pensar en tokens es pensar en probabilidades, en contexto y en eficiencia.
Y cuando entiendes eso, dejas de usar la herramienta como usuario casual y comienzas a usarla como estratega.