¿Qué es GPT-3 (Generative Pre-trained Transformer 3)?
- ¿Qué es GPT-3 (Generative Pre-trained Transformer 3)?
- Antes de GPT-3: el contexto histórico de los modelos GPT
- Qué significa realmente Generative Pre-trained Transformer
- Por qué GPT-3 fue un punto de inflexión en 2020
- Cómo funciona GPT-3 por dentro
- Qué puede hacer realmente GPT-3 (sin exageraciones)
- Limitaciones reales de GPT-3
- GPT-3 como punto de partida del boom de la IA generativa
Cuando alguien pregunta qué es GPT-3, casi siempre recibe una respuesta rápida: “un modelo de lenguaje con 175 mil millones de parámetros creado por OpenAI”. Es correcto. Pero es insuficiente.
GPT-3 no fue solo un modelo grande. Fue el punto en el que los modelos de lenguaje dejaron de ser experimentos académicos y comenzaron a comportarse como sistemas capaces de generar texto coherente, creativo y funcional a escala pública.
Aquí está la hipótesis que debes entender desde el inicio: GPT-3 no marcó una mejora incremental. Marcó un cambio de percepción. Demostró que el escalamiento masivo de parámetros podía producir comportamientos emergentes que antes no se veían con claridad en modelos más pequeños.
Para comprender por qué fue tan disruptivo, primero necesitas entender el contexto en el que apareció.
Antes de GPT-3: el contexto histórico de los modelos GPT
La serie GPT comenzó antes. GPT-1 introdujo la arquitectura basada en Transformer para generación de texto. GPT-2 sorprendió por su capacidad de producir textos largos y coherentes, aunque con limitaciones evidentes.
Pero todavía se percibían como modelos experimentales.
En 2020, cuando OpenAI presentó GPT-3, el salto fue cuantitativo y cualitativo. Pasó de miles de millones de parámetros a 175 mil millones. Ese aumento no fue simplemente numérico. Cambió el comportamiento observable del modelo.
Por primera vez, un modelo podía realizar tareas sin entrenamiento específico adicional, solo mediante instrucciones en lenguaje natural. Traducción, redacción, resumen, generación de código, simulación de estilos. Todo emergía desde el mismo sistema preentrenado.
GPT-3 no fue el primer Transformer. Fue el primero en demostrar lo que el escalamiento extremo podía desbloquear.
En la siguiente sección vamos a desmontar el nombre completo —Generative Pre-trained Transformer 3— para entender exactamente qué significa cada parte y por qué no es solo una etiqueta técnica.

Qué significa realmente Generative Pre-trained Transformer
Para entender qué es GPT-3, no basta con memorizar que tiene 175 mil millones de parámetros. Necesitas desmontar su nombre completo: Generative Pre-trained Transformer 3. Cada palabra describe una decisión técnica clave.
No es un nombre comercial. Es una arquitectura.
Generative
“Generative” significa que el modelo no clasifica ni etiqueta texto. Lo produce.
A diferencia de modelos diseñados para responder sí/no o asignar categorías, GPT-3 genera secuencias completas token por token. Su funcionamiento se basa en predecir cuál es el siguiente token más probable dado el contexto anterior.
No responde con reglas programadas. Responde por probabilidad estadística.
Y eso cambia todo.
Pre-trained
“Pre-trained” indica que el modelo fue entrenado previamente con enormes cantidades de texto antes de ser utilizado en tareas específicas.
Ese entrenamiento inicial no se hizo para una tarea concreta. No fue “entrenado para resumir” o “entrenado para traducir”. Fue entrenado para modelar lenguaje en general.
Esto permite algo fundamental: la capacidad de realizar tareas nuevas solo a través de instrucciones. Sin reentrenamiento adicional, el modelo puede adaptarse mediante lo que se conoce como in-context learning.
Ese fue uno de los saltos más visibles.
Transformer
Aquí está la base arquitectónica.
El Transformer es una arquitectura de red neuronal presentada en 2017 que utiliza mecanismos de atención para procesar secuencias completas de texto en paralelo. En lugar de leer palabra por palabra de manera secuencial, el modelo analiza relaciones entre tokens dentro del contexto completo.
GPT-3 utiliza esta arquitectura a gran escala.
El mecanismo de atención permite que el modelo determine qué partes del texto son más relevantes para predecir el siguiente token. No “entiende” como un humano. Detecta patrones de co-ocurrencia en espacios vectoriales de alta dimensión.
Y ahora empieza a verse por qué no fue solo una versión más grande.
Por qué GPT-3 fue un punto de inflexión en 2020
Hasta GPT-2, el crecimiento de modelos de lenguaje parecía una progresión técnica interesante, pero todavía limitada. Con GPT-3, el panorama cambió.
Cuando OpenAI anunció en 2020 que el modelo alcanzaba 175 mil millones de parámetros, no se trataba solo de una cifra impresionante. Se trataba de demostrar que el escalamiento masivo podía generar comportamientos que no habían sido programados explícitamente.
Aquí es donde aparece el concepto clave: capacidades emergentes.
175 mil millones de parámetros
Un parámetro en una red neuronal es, simplificando, un peso numérico que ajusta cómo el modelo procesa la información. Más parámetros implican mayor capacidad para modelar relaciones complejas dentro de los datos.
GPT-3 multiplicó por más de diez el tamaño de GPT-2. Ese salto permitió que el modelo capturara patrones lingüísticos con mayor profundidad y generalidad.
Pero lo verdaderamente interesante no fue solo la escala. Fue el efecto de esa escala.
El modelo comenzó a mostrar habilidades que no habían sido entrenadas de forma específica: responder preguntas, traducir, resumir, generar código, completar instrucciones complejas.
No porque alguien le enseñara cada tarea. Sino porque el entrenamiento masivo sobre lenguaje general le permitió adaptarse mediante contexto.
Escalamiento y habilidades emergentes
Antes de GPT-3, se asumía que para cada tarea se necesitaba entrenamiento específico. Este modelo desafió esa idea.
Mediante few-shot learning —es decir, proporcionando ejemplos dentro del propio prompt— el modelo podía ejecutar tareas nuevas sin modificar sus parámetros internos.
Esto fue disruptivo por una razón estratégica: redujo la necesidad de reentrenamiento para cada caso de uso.
El modelo no “aprendía” en tiempo real. Pero podía adaptarse dentro del contexto de la conversación.
Ese comportamiento cambió la forma en que empresas y desarrolladores comenzaron a pensar en modelos de lenguaje.
GPT-3 no fue simplemente más grande. Fue el modelo que hizo evidente que la escala podía desbloquear versatilidad.
Cómo funciona GPT-3 por dentro
Ahora que entiendes por qué GPT-3 fue disruptivo, toca ir al núcleo técnico. Porque cuando alguien pregunta qué es GPT-3, en realidad debería preguntarse: ¿cómo procesa texto internamente?
La respuesta es menos mística de lo que parece.
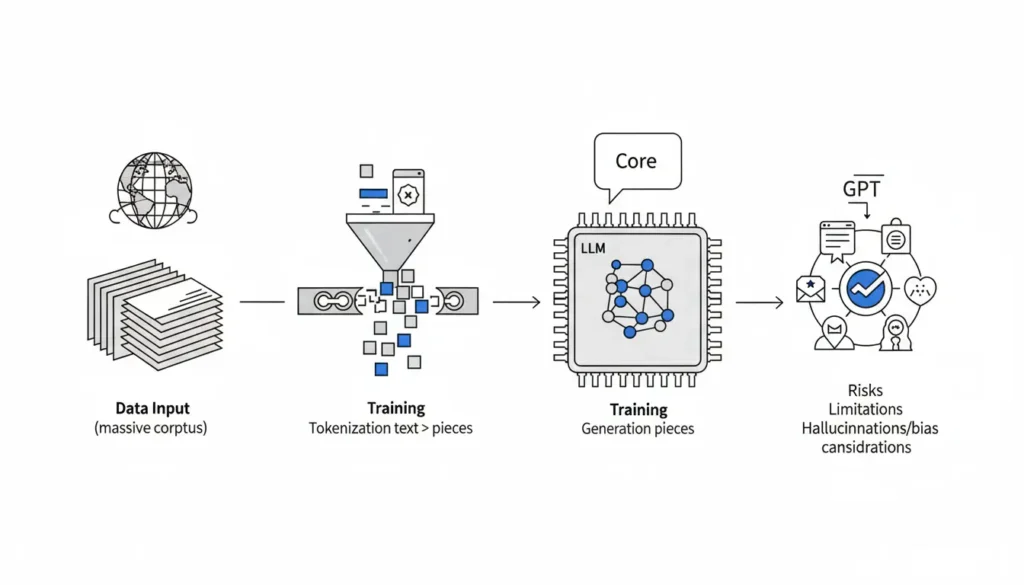
GPT-3 no “razona” como un humano. No tiene comprensión consciente. Funciona mediante una arquitectura Transformer que analiza relaciones entre tokens y predice el siguiente elemento más probable en una secuencia.
Todo se reduce a probabilidad condicionada.
Arquitectura Transformer
La base de GPT-3 es la arquitectura Transformer, introducida en 2017. Su innovación principal fue el mecanismo de atención (self-attention), que permite que cada token en una secuencia evalúe su relación con todos los demás tokens dentro del contexto.
En lugar de leer palabra por palabra de forma lineal, el modelo procesa la secuencia completa en paralelo. Calcula qué partes del texto son más relevantes para cada predicción.
Ese mecanismo es lo que le permite mantener coherencia en párrafos largos y relacionar conceptos que aparecen en distintas partes del contexto.
No hay memoria consciente. Hay atención matemática.
Predicción del siguiente token
En última instancia, este modelo opera bajo un principio simple: dada una secuencia de tokens, predice cuál es el siguiente más probable.
Ese proceso se repite token por token hasta completar una respuesta.
No “sabe” que está escribiendo un ensayo.
No “entiende” que está resolviendo un problema.
Está estimando probabilidades en un espacio vectorial de alta dimensión, basado en patrones aprendidos durante el preentrenamiento.
Y aquí está lo interesante.
Cuando el modelo alcanza cierto tamaño —como ocurrió con GPT-3— esa predicción estadística empieza a parecer comprensión. Pero sigue siendo estadística.
Qué puede hacer realmente GPT-3 (sin exageraciones)
Después de entender qué es GPT-3 y cómo funciona por dentro, la pregunta práctica es inevitable: ¿qué puede hacer en la realidad?
La respuesta debe ser equilibrada. Ni hype exagerado ni reducción técnica fría.
GPT-3 puede:
- Generar texto coherente en múltiples estilos.
- Resumir información.
- Traducir entre idiomas.
- Completar instrucciones en lenguaje natural.
- Generar código básico.
- Simular diálogos.
- Reformular contenido.
Pero aquí está la clave.
No hace estas tareas porque “entienda” el mundo. Las hace porque modela patrones lingüísticos con suficiente precisión estadística como para producir resultados funcionales.
La calidad depende del prompt, del contexto y del tipo de tarea.
Limitaciones reales de GPT-3
Si solo explicas lo que puede hacer, el artículo queda incompleto.
GPT-3 también tiene limitaciones claras:
- Puede inventar información (alucinaciones).
- No tiene acceso en tiempo real a bases de datos externas.
- No posee comprensión factual garantizada.
- Puede reproducir sesgos presentes en datos de entrenamiento.
- Su conocimiento está limitado al periodo de entrenamiento.
Además, este modelo no fue diseñado como un modelo conversacional optimizado. Versiones posteriores, como GPT-3.5 y GPT-4, ajustaron comportamiento mediante técnicas adicionales como reinforcement learning from human feedback.
Es importante entender esto: GPT-3 fue un modelo fundacional. No fue la versión final del sistema conversacional que hoy asociamos con ChatGPT.
GPT-3 como punto de partida del boom de la IA generativa
Si hoy la inteligencia artificial generativa es tema central en empresas, medios y estrategia digital, es en gran parte porque demostró que el lenguaje podía escalar.
Cuando OpenAI lanzó GPT-3 en 2020, no solo presentó un modelo más grande. Presentó una prueba de concepto a escala global: el lenguaje podía modelarse de forma suficientemente robusta como para ejecutar tareas diversas sin reentrenamiento específico.
Eso cambió la conversación.
Antes de GPT-3, los modelos de lenguaje eran avances técnicos interesantes. Después de GPT-3, se volvieron infraestructura.
Chatbots, generación de contenido, automatización de soporte, redacción asistida, copilotos de código. Todo el ecosistema actual se apoya en esa demostración inicial de escalamiento.
Pero aquí está la lectura estratégica que debes quedarte.
No fue el final. Fue el inicio visible del ciclo comercial masivo de los grandes modelos de lenguaje. A partir de ahí llegaron iteraciones más refinadas, modelos más seguros y arquitecturas más eficientes.
Si entiendes qué es este modelo, entiendes el momento en que la IA dejó de ser laboratorio y empezó a ser herramienta productiva.
Y cuando comprendes ese punto de inflexión, también entiendes por qué hoy hablamos de modelos generativos como parte central de la estrategia digital.
GPT-3 no fue solo una versión. Fue un cambio de paradigma.