¿Qué es un LLM (Large Language Model)?
- ¿Qué es un LLM (Large Language Model)?
- Antes de los LLM: cómo funcionaban los modelos de lenguaje tradicionales
- Qué significa realmente “Large Language Model”
- Cómo funciona un LLM por dentro
- Por qué el escalamiento cambia el comportamiento
- Qué pueden hacer realmente los LLM
- Limitaciones y riesgos éticos
- Los LLM como infraestructura, no como moda
Cuando alguien pregunta qué es un LLM, suele recibir una respuesta rápida: “un modelo de inteligencia artificial entrenado con grandes cantidades de texto”. Es correcto, pero incompleto. Porque lo que realmente distingue a un LLM no es solo el volumen de datos. Es el efecto que produce esa escala sobre su comportamiento.
Un LLM —Large Language Model— es un modelo de lenguaje basado en redes neuronales profundas, generalmente construido sobre arquitectura Transformer, capaz de procesar y generar texto mediante predicción estadística de tokens. Pero aquí está la hipótesis central: lo que hace disruptivo a un LLM no es que entienda lenguaje. Es que modela patrones a una escala suficiente como para simular comprensión.
Antes de entrar en su funcionamiento interno, necesitas entender algo clave. Los LLM no aparecieron de la nada. Son el resultado de una evolución progresiva en el procesamiento de lenguaje natural.
Antes de los LLM: cómo funcionaban los modelos de lenguaje tradicionales
Antes de los LLM, los modelos de lenguaje eran más pequeños, más específicos y más limitados. Funcionaban bajo arquitecturas como RNN o LSTM, que procesaban texto de manera secuencial y tenían dificultades para mantener contexto largo.
Esos modelos podían realizar tareas concretas si se entrenaban específicamente para ello. Pero no eran versátiles. Cada tarea requería un modelo ajustado para un objetivo determinado.
La llegada de la arquitectura Transformer en 2017 cambió esa dinámica. Permitió procesar secuencias completas en paralelo mediante mecanismos de atención, mejorando drásticamente la capacidad de manejar contexto.
A partir de ahí, el escalamiento comenzó.
Los modelos dejaron de entrenarse para tareas individuales y empezaron a entrenarse para modelar lenguaje en general. Cuando esa escala alcanzó cientos de miles de millones de parámetros, surgió lo que hoy llamamos LLM.

Qué significa realmente “Large Language Model”
Cuando lees Large Language Model, puede parecer solo una etiqueta técnica. Pero cada palabra tiene peso estructural. No es una descripción genérica. Es una definición operativa.
Para entender qué es un LLM, necesitas desmontar el término.
Large
“Large” no significa simplemente “mucho texto”. Significa escala en tres dimensiones:
- Cantidad de parámetros.
- Volumen de datos de entrenamiento.
- Capacidad computacional utilizada.
Un LLM moderno puede tener miles de millones o incluso billones de parámetros. Esos parámetros son los pesos numéricos que ajustan cómo el modelo transforma una secuencia de tokens en la siguiente predicción.
La escala cambia el comportamiento.
Cuando un modelo alcanza cierto tamaño, empiezan a aparecer capacidades emergentes. No fueron programadas explícitamente. Emergen del entrenamiento masivo. Esa es la diferencia crítica entre un modelo NLP tradicional y un LLM.
Language
El término “Language” indica que el modelo está entrenado para modelar lenguaje humano en sentido amplio. No solo clasifica frases. No solo responde preguntas cerradas.
Aprende patrones estadísticos de cómo se organiza el lenguaje en múltiples contextos: narrativo, técnico, conversacional, académico.
No entiende significado como un humano. Pero modela relaciones entre tokens con suficiente profundidad como para producir texto coherente y contextualizado.
Model
Finalmente, “Model” implica que no estamos ante una base de datos ni un sistema de reglas. Es una red neuronal entrenada para aproximar distribuciones de probabilidad sobre secuencias de texto.
Un LLM no almacena respuestas prediseñadas. Calcula probabilidades en tiempo real.
Dado un contexto, estima cuál es el siguiente token más probable. Luego repite el proceso hasta completar la secuencia.
Ese mecanismo simple —repetido millones de veces durante entrenamiento— produce comportamiento complejo.
Cómo funciona un LLM por dentro
Si ya entiendes qué es un LLM, ahora toca ir al mecanismo interno. Porque mientras no comprendas cómo procesa el texto, seguirás viendo el resultado como algo casi mágico.
Un LLM (Large Language Model) no trabaja con palabras en sentido humano. Trabaja con tokens. Y sobre esos tokens aplica operaciones matemáticas dentro de una arquitectura Transformer.
No hay intuición. Hay cálculo probabilístico.
Tokenización
El primer paso es fragmentar el texto en tokens.
Un token puede ser una palabra completa, parte de una palabra, un signo de puntuación o incluso un espacio con prefijo. El modelo no procesa frases como tú las ves. Las convierte en secuencias numéricas.
Cada token se transforma en un identificador y luego en un vector numérico llamado embedding. Ese vector captura relaciones estadísticas aprendidas durante el entrenamiento.
Sin tokenización, el modelo no puede operar.
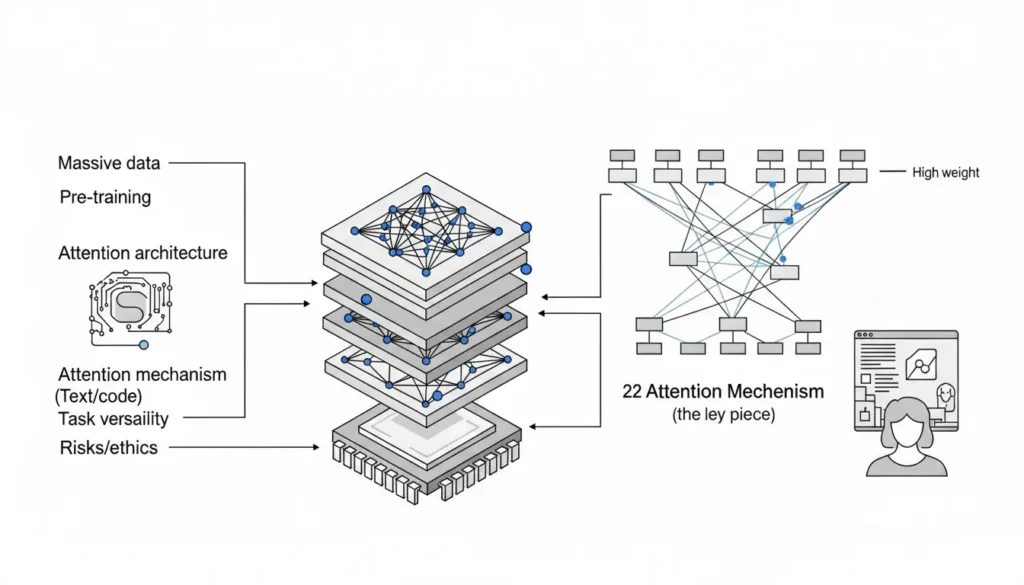
Transformer y self-attention
Una vez tokenizado el texto, entra en juego la arquitectura Transformer.
El mecanismo clave es la self-attention. Esto permite que cada token evalúe su relación con todos los demás tokens dentro del contexto.
No se procesa palabra por palabra de forma lineal. Se analizan relaciones en paralelo. El modelo calcula qué partes del texto son más relevantes para predecir el siguiente token.
Ese sistema de atención es lo que permite mantener coherencia en textos largos y relacionar ideas separadas por varios párrafos.
No es memoria consciente. Es ponderación matemática.
Predicción del siguiente token
En esencia, un LLM funciona bajo un principio sencillo: dada una secuencia de tokens, predice el siguiente más probable.
Esa predicción se convierte en el nuevo token del texto. Luego el proceso se repite.
Token tras token.
Cuando el modelo es suficientemente grande —como ocurre con LLM modernos— esa predicción estadística empieza a parecer comprensión. Pero sigue siendo probabilidad condicionada.
Y aquí es donde la escala empieza a marcar la diferencia.
Por qué el escalamiento cambia el comportamiento
Aquí es donde muchos subestiman lo que significa un LLM.
No es solo un modelo más grande. Es un modelo que, al alcanzar cierta escala, empieza a mostrar comportamientos que no estaban explícitamente programados.
Esto se conoce como capacidades emergentes.
Cuando un modelo pequeño predice el siguiente token, lo hace con un nivel limitado de generalización. Puede completar frases simples, pero falla en tareas complejas.
Cuando el número de parámetros crece exponencialmente y el volumen de datos aumenta, el modelo comienza a capturar patrones más abstractos.
No porque alguien lo haya diseñado para “razonar”. Sino porque la escala permite modelar relaciones más profundas entre conceptos.
En modelos pequeños, necesitas entrenamientos específicos para cada tarea.
En LLM grandes, muchas tareas aparecen solo con instrucciones en el prompt.
Eso cambió el paradigma.
Traducción, resumen, generación de código, explicación técnica. No fueron módulos añadidos. Emergen del entrenamiento masivo sobre lenguaje general.
La escala no solo aumenta capacidad. Cambia cualitativamente el comportamiento.
Pero aquí es donde conviene mantener rigor.
Emergente no significa perfecto. No significa consciente. No significa infalible.
Significa que la complejidad estadística alcanzó un punto donde el modelo puede generalizar con mayor flexibilidad.
Qué pueden hacer realmente los LLM
Después de entender qué es un LLM (Large Language Model) y cómo funciona por dentro, la pregunta práctica es inevitable: ¿para qué sirve en el mundo real?
Aquí conviene mantener equilibrio. Ni entusiasmo desmedido ni reducción simplista.
Un LLM puede:
- Generar texto coherente en múltiples estilos.
- Resumir documentos extensos.
- Traducir entre idiomas.
- Responder preguntas abiertas.
- Generar código funcional.
- Clasificar y reformular contenido.
- Analizar patrones en texto.
Pero el punto no es la lista.
El punto es que todas esas tareas surgen del mismo mecanismo: predicción del siguiente token basada en patrones aprendidos durante el entrenamiento masivo.
No hay módulos separados para cada función. Hay un único modelo general que adapta su comportamiento según el contexto proporcionado.
Y eso es lo que lo vuelve versátil.
Limitaciones y riesgos éticos
Si solo explicas lo que pueden hacer, el análisis queda incompleto.
Los LLM también presentan limitaciones claras:
- Pueden generar información incorrecta con apariencia convincente.
- No tienen verificación factual interna.
- Pueden reproducir sesgos presentes en los datos de entrenamiento.
- No poseen conciencia ni comprensión real.
- No acceden a información actualizada a menos que estén conectados a sistemas externos.
Además, su uso plantea desafíos éticos relacionados con desinformación, privacidad y automatización de procesos sensibles.
Entender qué es un LLM implica también entender sus límites.
No es una base de datos.
No es un motor de búsqueda.
No es una mente artificial.
Es un modelo estadístico de lenguaje a gran escala.
Y ahora podemos cerrar el círculo estratégico.
Los LLM como infraestructura, no como moda
Si entiendes realmente qué es un LLM, dejas de verlo como una herramienta llamativa y empiezas a verlo como infraestructura.
Un Large Language Model no es una aplicación concreta. Es una base tecnológica sobre la que se construyen múltiples aplicaciones: asistentes conversacionales, copilotos de código, sistemas de análisis de documentos, automatización de soporte, generación de contenido y más.
Lo que antes requería sistemas especializados para cada tarea, hoy puede ejecutarse desde un mismo modelo general entrenado a gran escala.
Ese cambio es estructural.
Los LLM no sustituyen el conocimiento humano. Amplifican la capacidad de procesar lenguaje. No eliminan la necesidad de criterio. Exigen mayor criterio.
Y aquí está la lectura estratégica final.
Cuando una tecnología se convierte en infraestructura, deja de ser tendencia y pasa a ser entorno. Los LLM ya están integrados en flujos de trabajo, plataformas y productos empresariales.
Entender qué es un LLM no es solo comprender un término técnico. Es comprender la base sobre la que se está reconfigurando el procesamiento de información en la era digital.
No es moda.
Es arquitectura.