Araña Web: Descubre su Importancia y Funcionamiento
- Araña Web: Descubre su Importancia y Funcionamiento
- Bots de IA: el nuevo conflicto por el contenido
- Cómo interpreta Google una web realmente
- Anatomía de una Araña: El Ciclo de Vida del Rastreo
- El problema moderno: JavaScript y renderizado SEO
- Tipología de Bots en 2026: Amigos, Enemigos y Parásitos
- Bots maliciosos y riesgos de seguridad
- La Economía del Rastreo: Dominando el Crawl Budget
- Protocolo de Control: Robots.txt y Meta Robots
- Auditoría Forense: ¿Quién visita tu web realmente?
- Tu web debe ser "rastreable" antes que "bonita"
- Las arañas web en la era de la IA generativa
- Las arañas web ya no solo organizan Internet: ahora deciden quién existe
Internet no es una “nube” etérea; es una biblioteca física inmensa y desorganizada. Para que alguien encuentre tu libro, necesitas un bibliotecario que lo fiche. Ese bibliotecario es la Araña Web (o Crawler).
En términos técnicos, una araña es un software automatizado que recorre Internet descargando e indexando contenido para que pueda ser recuperado posteriormente. Sin ellas, tu web sería invisible. Si Googlebot no pasa por tu URL, para el mundo no existes.
Pero cuidado: en 2026, el juego ha cambiado. Ya no solo te visita Google para traerte tráfico. Ahora te visitan Bots de Inteligencia Artificial (como los de OpenAI o Anthropic) para “leer” tu contenido y entrenar sus modelos, a menudo sin enviarte ni una sola visita a cambio. La gestión de bots ya no es solo SEO; es defensa de propiedad intelectual.
Bots de IA: el nuevo conflicto por el contenido
Durante años, el acuerdo implícito era simple:
Google rastreaba tu contenido y, a cambio, te enviaba tráfico. Con los bots de IA, esa relación cambió.
Muchos modelos de lenguaje consumen enormes cantidades de contenido para:
- entrenar sistemas,
- generar respuestas,
- resumir información,
- o alimentar experiencias conversacionales.
El problema es que, muchas veces, esa extracción ocurre sin devolver visitas equivalentes. Aquí aparece una tensión estratégica enorme.
Algunas empresas prefieren bloquear estos bots para proteger:
- propiedad intelectual,
- monetización,
- y recursos de servidor.
Otras permiten acceso porque quieren aumentar presencia dentro de ecosistemas IA.
La decisión ya no es únicamente técnica. Es una decisión de negocio y distribución digital.

Cómo interpreta Google una web realmente
Google no “ve” una web como la ve un humano.
No interpreta colores, diseño bonito o animaciones complejas como señales principales. Lo que realmente analiza es una red de relaciones entre URLs, enlaces internos, jerarquías y contenido semántico.
Cada página funciona como un nodo conectado dentro de un ecosistema.
Y aquí aparece un error crítico:
Muchos sitios están diseñados para usuarios humanos… pero son extremadamente difíciles de interpretar para los bots.
Cuando una arquitectura es confusa, el crawler tiene problemas para:
- descubrir contenido,
- entender prioridades,
- distribuir autoridad,
- y procesar relaciones temáticas.
Por eso el rastreo moderno ya no consiste únicamente en “permitir acceso”.
Consiste en facilitar interpretación algorítmica.
Y cuanto más fácil sea para Google comprender tu ecosistema, más eficiente será la indexación y consolidación de relevancia.
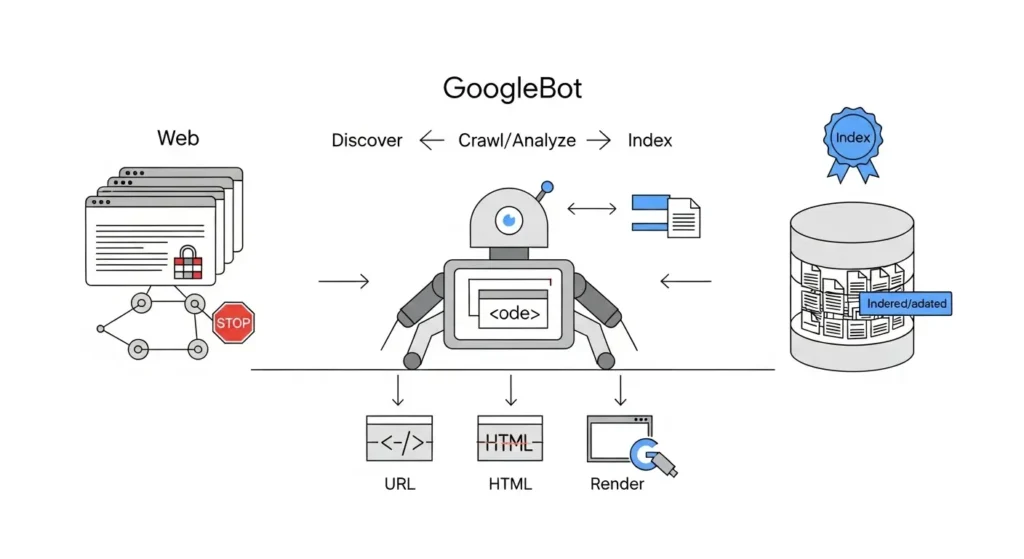
Anatomía de una Araña: El Ciclo de Vida del Rastreo
Para dominar el rastreo, debes entender que no es un paso único. Es un ciclo industrial de cuatro fases. Si tu web falla en una, el proceso se rompe.

Descubrimiento (Discovery)
Antes de leerte, la araña tiene que encontrarte. Los bots no adivinan URLs; las descubren siguiendo pistas.
- Enlaces (Links): La araña salta de un enlace a otro. Si una página conocida enlaza a la tuya, la araña la añade a su lista de “pendientes” (seed list).
- Sitemaps XML: Es tu mapa oficial. Le entregas al bot una lista directa de todas las URLs que quieres que visite, saltándose la necesidad de descubrirlas orgánicamente.
Rastreo (Crawling)
Es el acto físico de visitar la página. El bot hace una petición a tu servidor y descarga el código.
- El Factor Velocidad: Aquí entra el Crawl Budget. Si tu servidor tarda 2 segundos en responder, el bot se aburre y se va. Gastas su tiempo (y dinero) y dejas páginas sin rastrear.
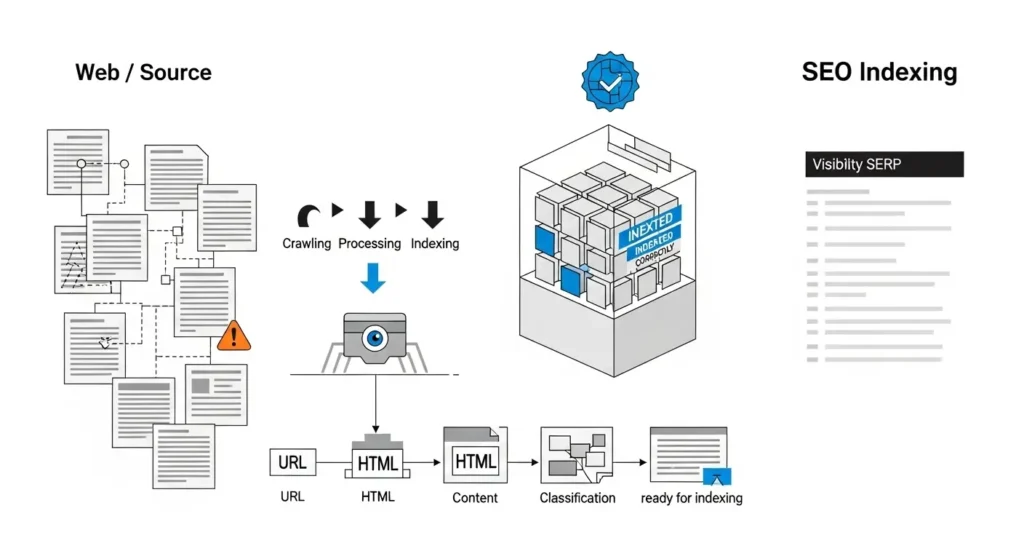
Procesamiento y Renderizado (The Black Box)
Una vez descargado, el contenido bruto es inútil. Debe ser procesado.
- Limpieza: El bot elimina el código HTML innecesario, normaliza formatos y extrae el texto y los enlaces.
- Renderizado: En la web moderna, esto es crítico. Si tu web depende de JavaScript para mostrar el contenido, el bot debe “ejecutar” la página como si fuera un navegador. Muchos bots básicos no pueden hacer esto, y ven tu página en blanco.
Indexación (Indexing)
El paso final. Si la página pasa los filtros de calidad, se guarda en el índice (la base de datos gigante).
- La Decisión: No todo lo rastreado se indexa. Si tienes contenido duplicado o etiquetas noindex, el bot procesará la página pero la descartará, no la guardará en la biblioteca.
Aquí tienes la continuación. Entramos en la zona de guerra: distinguir entre los bots que te traen tráfico y los que te roban datos, y cómo gestionar tu “dinero” (Crawl Budget).
He extraído la lista de bots de IA directamente del análisis de Cloudflare para que sepas exactamente a quién bloquear y a quién permitir.

El problema moderno: JavaScript y renderizado SEO
La web moderna depende cada vez más de JavaScript. Y ahí aparece uno de los mayores desafíos técnicos del SEO actual.
Cuando una página utiliza renderizado del lado del cliente (CSR), el contenido principal no existe inmediatamente dentro del HTML inicial. El navegador debe ejecutar scripts antes de mostrar información real.
Eso crea un problema importante para los crawlers.
Googlebot puede renderizar JavaScript, sí. Pero el proceso consume muchos más recursos que rastrear HTML limpio.
Aquí aparece el concepto de Render Budget.
Cuanto más pesada y compleja sea una página JavaScript:
- más tiempo consume,
- más recursos requiere,
- y mayor probabilidad existe de que Google procese parcialmente el contenido o retrase su indexación.
Por eso frameworks modernos como:
- Next.js,
- Nuxt,
- o arquitecturas SSR
han ganado tanta relevancia en SEO técnico. Reducen fricción de renderizado y facilitan comprensión algorítmica inmediata.
Tipología de Bots en 2026: Amigos, Enemigos y Parásitos
No todos los bots son iguales. En tu archivo de logs verás miles de peticiones, pero debes clasificarlas en tres categorías tácticas para configurar tu defensa.
Los VIPs (Motores de Búsqueda)
Son los únicos que te traen tráfico directo. Debes ponerles la alfombra roja.
- Googlebot: El rey. Se divide en Googlebot Desktop y Smartphone.
- Bingbot (Microsoft): Alimenta a Bing, Yahoo! y DuckDuckGo.
- Yandex y Baidu: Críticos solo si operas en Rusia o China.
Los Recolectores de IA (El Nuevo Desafío)
Aquí está el cambio de paradigma. Estos bots no indexan para enviarte visitas; rastrean para entrenar sus Modelos de Lenguaje (LLM) o dar respuestas en tiempo real sin citarte.
- GPTBot (OpenAI): Rastrea para entrenar futuros modelos GPT. Si lo bloqueas, tu contenido no será “conocido” por ChatGPT.
- ChatGPT-User: Actúa en tiempo real cuando un usuario le pide a ChatGPT que busque algo en la web.
- ClaudeBot (Anthropic) y CCBot (Common Crawl): Alimentan a otros modelos masivos.
Decisión Estratégica: ¿Bloquear o no? Si eres un medio de noticias que vive de la publicidad, estos bots consumen tus recursos y no te dan clics. Muchos deciden bloquearlos vía robots.txt. Si eres una marca corporativa, quizás quieras que la IA “sepa” quién eres para hablar bien de ti.
Scrapers y Parásitos
Bots que copian tu contenido para duplicarlo en otras webs o robar precios.
- El daño: Consumen ancho de banda, ralentizan tu servidor para usuarios reales y pueden duplicar tu contenido en dominios basura.
- La defensa: A diferencia de los bots legítimos, estos suelen ignorar el archivo robots.txt. Se combaten a nivel de servidor (CDN/Firewall).
Bots maliciosos y riesgos de seguridad
No todos los bots buscan indexar contenido. Muchos intentan explotar vulnerabilidades, recolectar datos o saturar infraestructura.
Los ataques automatizados más comunes incluyen:
- scraping masivo,
- credential stuffing,
- exploración de vulnerabilidades,
- spam automatizado,
- y ataques DDoS básicos.
Aquí aparece un error frecuente:
Muchos sitios solo optimizan para Googlebot y olvidan completamente la protección del servidor.
Eso puede provocar:
- ralentización extrema,
- consumo innecesario de recursos,
- y degradación del rendimiento SEO.
Porque sí:
la seguridad también afecta rastreo.
Un servidor saturado responde peor. Y cuando responde peor, Googlebot rastrea menos.
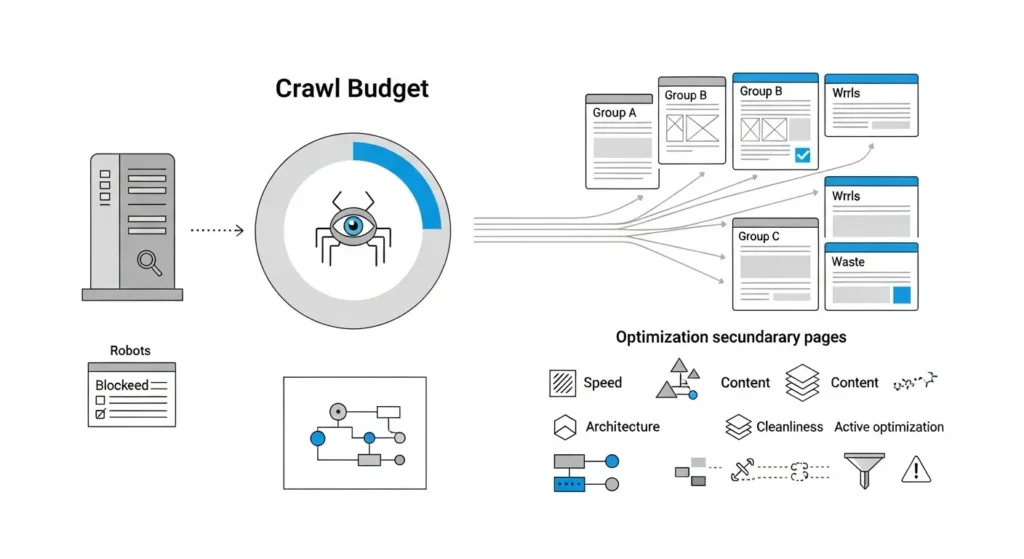
La Economía del Rastreo: Dominando el Crawl Budget
Google no tiene recursos infinitos. Asigna un Presupuesto de Rastreo (Crawl Budget) a cada dominio, basado en su autoridad y velocidad. Si gastas este presupuesto en basura, tus páginas nuevas tardarán semanas en aparecer.
Velocidad de Servidor = Dinero
Esta es la ecuación fundamental. Si Googlebot llega a tu web y el servidor tarda 2 segundos en responder, el bot “gasta” más presupuesto en una sola URL.
- Consecuencia: Si tu web es lenta, Google rastrea menos páginas por sesión.
- Solución: Un servidor rápido permite que el bot rastree 10 páginas en el tiempo que antes rastreaba Multiplicas tu indexación sin crear más contenido.
Las Trampas de Rastreo (Crawl Traps)
Son agujeros negros donde el bot entra y se pierde, desperdiciando presupuesto.
- URLs con Parámetros Infinitos: Filtros de productos que generan URLs tipo ?color=rojo&talla=L&tela=algodon….
- Redirecciones en Cadena: Si la Página A redirige a la B, y la B a la C, estás obligando al bot a hacer 3 peticiones para ver 1 contenido.
- Errores 404 (Soft y Hard): Enlaces internos que llevan a callejones sin salida. Si tienes miles de estos, estás quemando presupuesto en la nada.
Arquitectura de Enlazado
Una estructura plana ahorra presupuesto. Si una página importante está a 5 clics de la home, el bot gastará mucho presupuesto “navegando” hasta llegar a ella.
- Táctica: Asegura que tus URLs críticas estén enlazadas desde niveles superiores para que el bot las encuentre rápido y fresco.
Aquí tienes la entrega final. Vamos a resolver el error técnico más común del SEO (bloqueo vs. desindexación) y a enseñarte a auditar como un forense.
Por qué el Crawl Budget destruye grandes e-commerce
En sitios pequeños, el Crawl Budget rara vez representa un problema crítico.
Pero en e-commerce gigantes o medios con millones de URLs, puede convertirse en una catástrofe silenciosa.
Aquí aparecen los verdaderos enemigos:
- filtros infinitos,
- parámetros dinámicos,
- paginaciones mal gestionadas,
- URLs duplicadas,
- y combinaciones faceteadas.
Cada una consume recursos de rastreo. El problema es que Googlebot tiene límites.
Si el crawler desperdicia tiempo rastreando miles de URLs inútiles, las páginas importantes:
- tardan más en indexarse,
- pierden frecuencia de rastreo,
- y reducen capacidad de actualización.
Por eso el SEO técnico moderno ya no consiste solo en crear contenido.
Consiste en administrar estratégicamente la atención del crawler.

Protocolo de Control: Robots.txt y Meta Robots
Aquí es donde el 90% de los webmasters cometen errores fatales. Confunden “no quiero que entres” con “no quiero que muestres esto”. Si usas la herramienta incorrecta, puedes desindexar tu web entera o, peor aún, dejar expuesto contenido privado.
La Diferencia de Vida o Muerte: Disallow vs. Noindex
Grábate esto a fuego: Robots.txt bloquea el rastreo, pero NO garantiza la desindexación.
- Robots.txt (Disallow):
Le dice al bot: “No pases por aquí”. Su objetivo principal es ahorrar Crawl Budget. - El peligro:
Si bloqueas una URL en robots.txt, Googlebot no podrá entrar. Sin embargo, si existen enlaces externos apuntando hacia esa página, Google puede indexarla igualmente mostrando el mensaje:
“No hay información disponible sobre esta página”. - Meta Robots (noindex):
Le dice al bot:
“Entra, procesa el contenido, pero no lo guardes en el índice”. - La regla crítica:
Para que noindex funcione, Google necesita poder rastrear la página.
Si bloqueas primero con Disallow, el crawler nunca verá la etiqueta noindex. - Nunca combines Disallow + Noindex en la misma URL si tu objetivo es desindexar correctamente.
X-Robots-Tag: El Francotirador Invisible
¿Qué pasa si quieres desindexar un PDF o una imagen? No puedes poner código HTML (<meta name…) dentro de un PDF.
- La Solución: Usa la cabecera HTTP X-Robots-Tag en tu servidor.
- El Uso: Configura tu servidor (Apache/Nginx) para enviar la instrucción noindex en las cabeceras de respuesta de archivos específicos. Es la forma profesional de controlar la indexación de archivos no HTML.
Estrategia de Bloqueo de IA (Robots.txt 0)
Si decides proteger tu propiedad intelectual de los modelos de IA, este es el código que debes añadir a tu archivo robots.txt hoy mismo:
Ejemplo:
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
Esto cierra la puerta a los recolectores de datos sin afectar a Googlebot .
Auditoría Forense: ¿Quién visita tu web realmente?
No confíes en lo que crees que pasa. Confía en los datos. Tienes dos formas de ver la realidad.
Informe de Estadísticas de Rastreo (Nivel Básico)
Google Search Console te ofrece una visión general de salud.
- Ruta: Ajustes > Estadísticas de rastreo > Abrir informe .
- Qué buscar:
- Picos de 5xx: Si el servidor falla cuando pasa el bot, tienes un problema grave de infraestructura.
- Tiempo de respuesta: Si la línea azul sube (ms de descarga), tu Crawl Budget baja.
Análisis de Logs (Log File Analysis – Nivel Dios)
Esta es la técnica que separa a los juniors de los seniors. Consiste en descargar los archivos brutos del servidor (access.log) para ver cada petición que se ha hecho a tu web.
- La Verdad Desnuda: Aquí verás si Googlebot está perdiendo el tiempo rastreando URLs con parámetros basura (?session_id=…) que ni sabías que existían.
- Detección de Impostores: Verás bots que dicen ser User-Agent: Googlebot pero vienen de IPs rusas o chinas. Bloquéalos por IP en el firewall.
Tu web debe ser “rastreable” antes que “bonita”
De nada sirve el mejor diseño o el mejor contenido si la puerta de la biblioteca está cerrada con llave. Las arañas web son tus socias de distribución; trátalas como tal.
Tu Checklist Final de Salud Técnica:
- Revisa tu Robots.txt: Asegúrate de no estar bloqueando recursos CSS/JS críticos para el renderizado .
- Audita tu Crawl Budget: Elimina cadenas de redirecciones y errores 40
- Decide sobre la IA: Define si quieres alimentar a los LLM o bloquearlos para proteger tu data .
- Diferencia Táctica: Usa noindex para contenido de baja calidad (Thin Content) y Disallow para zonas administrativas o scripts.
El consejo definitivo: Una web saludable es aquella por la que el bot fluye sin fricción. Si facilitas el trabajo de la araña, Google facilitará que los usuarios te encuentren .
Las arañas web en la era de la IA generativa
El rastreo ya no alimenta únicamente motores de búsqueda tradicionales.
Ahora también alimenta sistemas de IA capaces de:
- responder preguntas,
- resumir contenido,
- generar recomendaciones,
- y construir respuestas conversacionales completas.
Eso cambia completamente la importancia estratégica de las arañas web.
Porque ya no compites solo por rankings.
Compites por interpretación algorítmica dentro de ecosistemas IA.
Las webs más fáciles de rastrear, renderizar y comprender tienen más probabilidades de convertirse en fuentes visibles dentro de:
- motores generativos,
- asistentes conversacionales,
- y respuestas enriquecidas.
En otras palabras:
El SEO técnico moderno ya no optimiza solo indexación.
Optimiza legibilidad para máquinas inteligentes.
Las arañas web ya no solo organizan Internet: ahora deciden quién existe
Durante años, las arañas web funcionaron como simples sistemas de rastreo e indexación.
Hoy son mucho más que eso.
Son los intermediarios entre tu contenido y los sistemas que interpretan Internet:
- motores de búsqueda,
- modelos de IA,
- asistentes conversacionales,
- plataformas de descubrimiento,
- y ecosistemas automatizados.
Por eso el rastreo moderno ya no consiste únicamente en permitir acceso técnico.
Consiste en construir sitios:
- fáciles de descubrir,
- rápidos de procesar,
- simples de interpretar,
- y eficientes de renderizar.
La mayoría de webs se obsesionan con diseño visual.
Las que realmente dominan SEO entienden algo más profundo:
Si el crawler no puede comprender correctamente tu ecosistema digital, tu contenido prácticamente no existe para el algoritmo.
Y en 2026, existir algorítmicamente es el verdadero punto de partida del posicionamiento.