¿Qué es el crawl budget?
Cuando alguien pregunta qué es el crawl budget, casi siempre recibe una definición simplificada: “es la cantidad de páginas que Google puede rastrear en tu sitio en un periodo determinado”.
Es correcta. Pero incompleta.
Porque el crawl budget no es un número fijo que Google te asigna como si fuera una cuota mensual. Es el resultado dinámico de cómo el buscador percibe tu sitio en términos de eficiencia, autoridad y necesidad de actualización.
Aquí está la hipótesis que debes entender desde el inicio: el crawl budget no es un problema de todos los sitios. Es un problema de eficiencia estructural en sitios complejos.
Si tu arquitectura es limpia, tu enlazado interno es coherente y tu contenido tiene valor, el rastreo fluye. Si tu sitio está lleno de URLs innecesarias, parámetros infinitos o duplicidades, el rastreo se diluye.
El crawl budget no es magia.
Es gestión de recursos algorítmicos.
La idea errónea: no es un número fijo
Muchos piensan que Google asigna un “presupuesto” estático a cada dominio. Como si existiera una cifra concreta que determina cuántas URLs pueden rastrearse cada día.
No funciona así.
Google ajusta el ritmo de rastreo según dos variables principales: capacidad y demanda. Si el servidor responde rápido y el sitio demuestra relevancia, el rastreo puede aumentar. Si el servidor es lento o el contenido carece de señales de valor, el ritmo puede reducirse.
El crawl budget no es una cifra almacenada en algún panel oculto.
Es una consecuencia del comportamiento de tu sitio.
Y para entenderlo con precisión, necesitamos separar sus dos componentes estructurales.

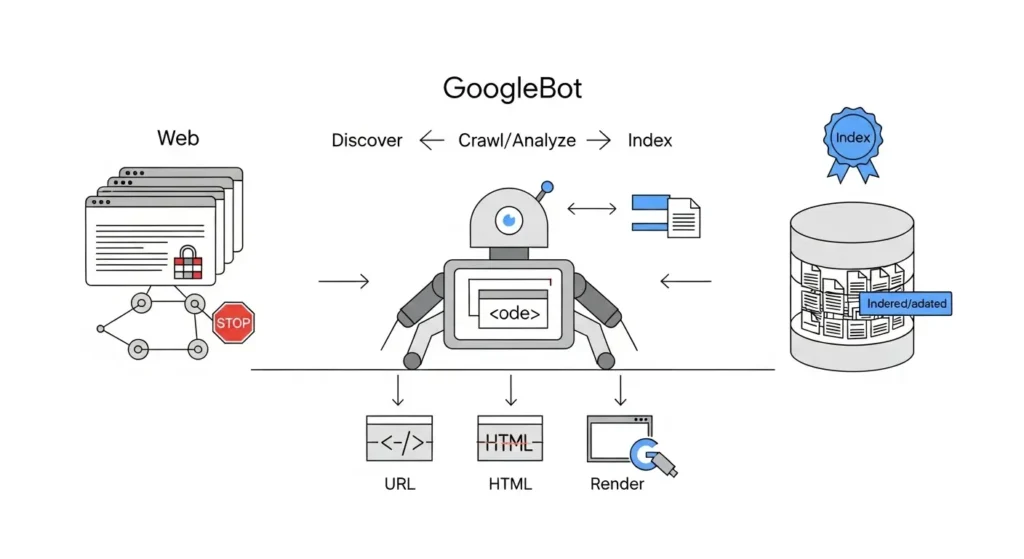
Cómo funciona realmente el crawl budget en Google
Si ya entendiste que el crawl budget no es un número fijo, ahora necesitamos entrar en su lógica operativa.
Google no reparte rastreo al azar. Ajusta recursos según dos componentes que trabajan juntos: capacidad de rastreo y demanda de rastreo.
El presupuesto final no es una cifra visible. Es el resultado de esa interacción.
Crawl Capacity Limit
La capacidad de rastreo depende principalmente de tu servidor.
Si Googlebot detecta que tu sitio responde rápido, sin errores frecuentes ni tiempos de carga elevados, puede aumentar el ritmo de rastreo sin afectar estabilidad.
Si el servidor devuelve errores 5xx, tiempos de respuesta altos o inestabilidad, Google reduce la frecuencia para no saturarlo.
Aquí no hay castigo. Hay protección.
Google no quiere dañar tu infraestructura. Si tu servidor es eficiente, tu capacidad aumenta. Si es frágil, el rastreo se limita.
La optimización técnica —Core Web Vitals, estabilidad del servidor, respuesta rápida— influye indirectamente.
Crawl Demand
La demanda de rastreo depende de la importancia percibida de tus URLs.
Si publicas contenido nuevo con frecuencia, si tus páginas reciben enlaces internos y externos, si actualizas secciones estratégicas, la demanda aumenta.
Google rastrea más donde percibe valor y cambio.
En cambio, si tienes miles de URLs sin tráfico, sin enlaces internos sólidos o con contenido duplicado, la demanda disminuye.
El algoritmo prioriza lo que considera relevante.
El crawl budget es, entonces, el equilibrio entre lo que Google puede rastrear sin dañar tu sitio y lo que considera que merece la pena rastrear.
No es una penalización. Es asignación de recursos.
Y ahora viene la parte importante.
No todos los sitios deben preocuparse por esto.
Cuándo el crawl budget es un problema real
Aquí es donde debes dejar de repetir definiciones y empezar a pensar estratégicamente.
El crawl budget solo se convierte en un problema cuando existe fricción estructural entre tamaño, arquitectura y calidad.
Si tu sitio tiene 50 o 200 URLs bien organizadas, con enlazado coherente y contenido útil, el rastreo no será tu cuello de botella. Google puede procesarlo sin dificultad.
El problema aparece en escenarios como estos:
Sitios con decenas de miles o millones de URLs.
E-commerce con filtros infinitos y parámetros dinámicos.
Portales con contenido generado automáticamente sin control de duplicidad.
Arquitecturas con paginaciones mal gestionadas.
Blogs con años de contenido thin sin limpieza editorial.
Aquí el rastreo se dispersa.
Google puede invertir recursos en URLs irrelevantes mientras deja sin priorizar páginas estratégicas.
No porque quiera penalizarte. Sino porque tu arquitectura le envía señales confusas.
También se vuelve crítico cuando existe alta rotación de contenido.
Sitios de noticias, marketplaces, catálogos dinámicos. Si Google no rastrea a tiempo, el contenido pierde ventana de visibilidad.
En estos casos, optimizar el crawl budget no es obsesión técnica. Es ventaja competitiva.
Pero hay algo que muchos ignoran.
En la mayoría de los sitios pequeños o medianos, el crawl budget no es el problema principal. Es una distracción que desvía atención de calidad y arquitectura interna.
Cuándo NO deberías preocuparte por el crawl budget
Aquí es donde muchos consultores cometen un error.
Hablan de crawl budget como si fuera el problema central de cualquier proyecto SEO. Y en la mayoría de los casos, no lo es.
Si tu sitio tiene menos de unas pocas miles de URLs indexables, buena velocidad de servidor y arquitectura clara, el rastreo no será tu limitante.
Google puede procesar ese volumen sin fricción.
Preocuparte por crawl budget en un sitio pequeño suele ser una forma sofisticada de evitar el verdadero trabajo: mejorar contenido, intención de búsqueda y enlazado interno estratégico.
El crawl budget se convierte en una obsesión innecesaria cuando:
No tienes problemas de indexación.
Tus páginas nuevas se rastrean con rapidez.
No hay señales masivas de duplicidad.
No manejas grandes volúmenes dinámicos.
En esos casos, tu energía debe ir a:
Arquitectura semántica.
Profundidad temática.
Experiencia de usuario.
Señales de autoridad.
El rastreo fluye cuando la estructura es limpia.
El verdadero riesgo no es tener poco crawl budget.
Es tener mala arquitectura que disperse el rastreo.
Y cuando el problema sí existe, la solución no es bloquear todo con robots.txt de forma reactiva.
La solución es optimizar con criterio.
Cómo optimizar el crawl budget sin obsesionarte
Si el crawl budget es eficiencia, entonces la optimización no consiste en bloquear por bloquear. Consiste en reducir fricción estructural.
El error común es pensar que basta con cerrar URLs en robots.txt. Eso puede reducir rastreo, pero no necesariamente mejora indexación estratégica.
Optimizar el crawl budget implica tres frentes.
Arquitectura interna
El rastreo sigue enlaces.
Si tus páginas estratégicas están a cinco o seis clics de profundidad, el presupuesto se diluye antes de llegar a ellas. Una arquitectura plana, con enlazado interno lógico y jerarquía clara, facilita que Googlebot priorice lo importante.
El enlazado no es solo UX. Es señal de relevancia interna.
Cuando estructuras correctamente categorías, subcategorías y contenidos pilares, reduces desperdicio de rastreo.
Gestión de parámetros y duplicidad
Uno de los mayores drenajes de crawl budget en sitios grandes son los parámetros dinámicos.
Filtros, ordenamientos, paginaciones mal controladas pueden generar miles de URLs distintas con contenido prácticamente idéntico.
Aquí la solución no es bloquear todo indiscriminadamente. Es:
Controlar indexación con etiquetas adecuadas.
Evitar generar URLs infinitas.
Eliminar thin content heredado.
Consolidar versiones duplicadas.
Menos ruido estructural significa más eficiencia.
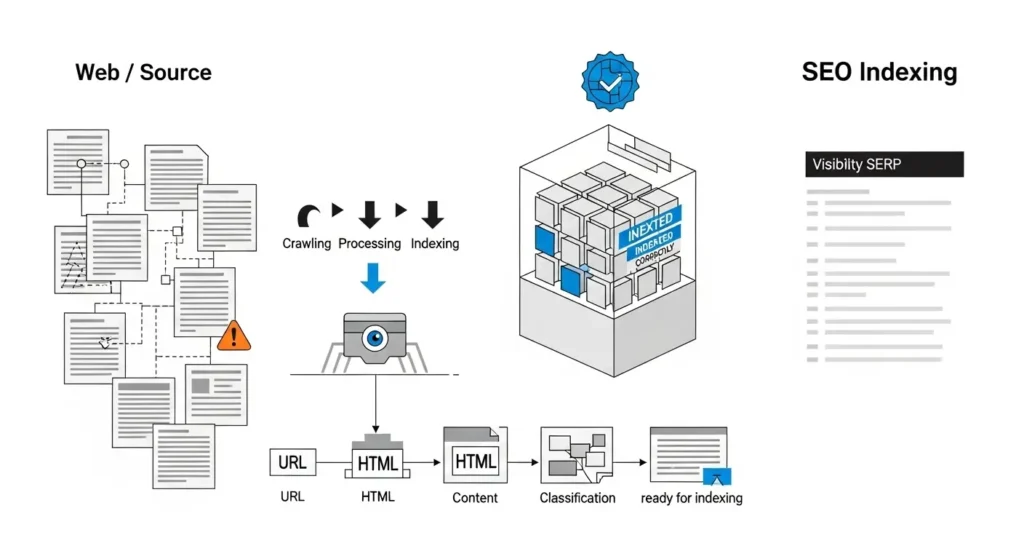
Logs y señales reales
Si gestionas un sitio grande, los logs del servidor se convierten en activo estratégico.
Ahí puedes observar qué URLs está rastreando realmente Googlebot, con qué frecuencia y cuáles ignora.
El crawl budget deja de ser teoría cuando analizas datos reales.
Sin logs, estás optimizando a ciegas.
Con logs, puedes identificar desperdicio, cuellos de botella y oportunidades.
Optimizar el crawl budget no es un ejercicio de paranoia técnica.
Es arquitectura inteligente.
Y ahora podemos cerrar el círculo.
Porque el crawl budget no es una palanca mágica para posicionar.
Es un sistema de eficiencia.
Y esa distinción es clave.
El crawl budget es eficiencia, no magia
Volvamos a la pregunta inicial: ¿qué es el crawl budget?
No es un número secreto que Google asigna.
No es una penalización oculta.
No es el principal problema de la mayoría de los sitios.
Es la consecuencia de cómo Google distribuye recursos de rastreo según capacidad técnica y demanda percibida.
Cuando tu arquitectura es limpia, tu contenido es relevante y tu servidor responde bien, el rastreo fluye de forma natural.
Cuando tu sitio está lleno de duplicidades, parámetros infinitos y thin content, el rastreo se dispersa.
El crawl budget no determina tu posicionamiento por sí mismo.
Pero sí puede convertirse en cuello de botella si gestionas mal la estructura en proyectos grandes.
La obsesión técnica no posiciona.
La eficiencia estructural sí.
Si entiendes esto, dejas de tratar el crawl budget como un mito SEO y empiezas a verlo como lo que realmente es: una variable operativa dentro de un sistema mucho más amplio de calidad, relevancia y arquitectura.
Y en SEO, la arquitectura siempre pesa más que la superstición.